
W jaki sposób porównano programy?
Do czterech najpopularniejszych programów antylagiatowych wrzucono fragment skopiowany z internetu w czterech wariantach, opisanych poniżej.
Próbka, która posłużyła do eksperymentu składała się z:
- Idealnej kopii artykułu w Internecie
- Kopii, w której zmieniono co 5 słowo
- Kopii, w której zmieniono co 4 słowo
- Kopii, w której zmieniono szyk słów
- Naturalnej parafrazie tekstu, gdzie wykorzystano: synonimy, zmianę szyku zdania, usuwanie wyrażeń, zmianę odmiany słów
Pobierz wykorzystaną próbkę tekstu

Zestawienie internetowych programów antyplagiatowych
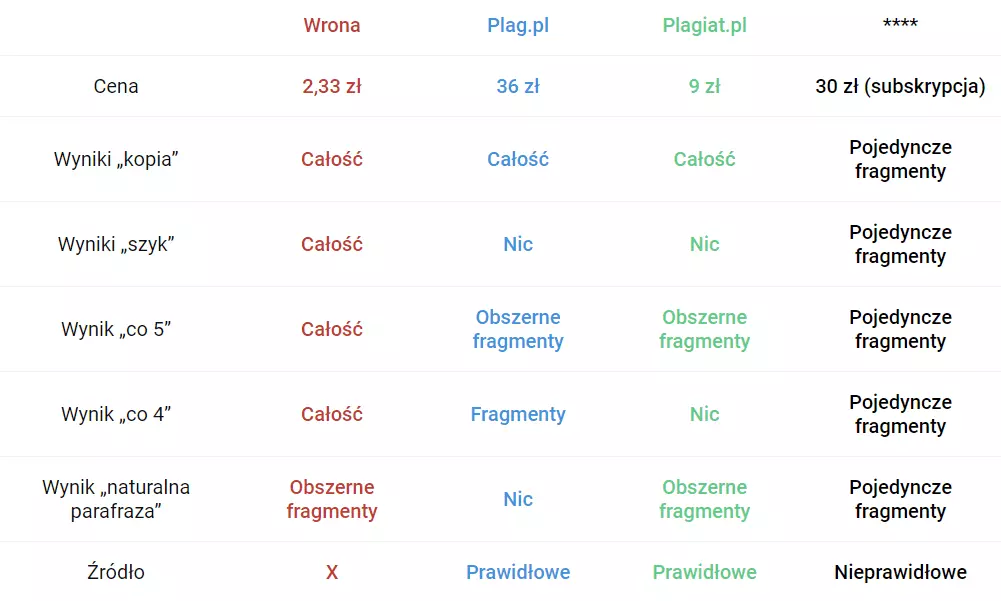

Antyplagiat Wrona – opinia: jest najczulszy i najlepiej przypomina algorytm w JSA, jest też bardzo tani. Jako jedyny rozpoznaje plagiat w zdaniach, gdzie zmieniony został szyk zdania, dokładnie tak jak oficjalny JSA. Program i płatności są też bardzo proste w obsłudze, dodatkowo posiada on możliwość porównania tylko fragmentów oznaczonych w oficjalnym programie JSA jako plagiat. Można więc dzięki niemu zweryfikować skuteczność poprawy plagiatu w pracy naukowej. Jego największą wadą jest natomiast fakt, że porównuje dwa teksty między sobą, a zatem nie mając tekstu źródłowego nie da się z niego skorzystać. Polecam wszystkim, aby korzystali z niego w trakcie pisania pracy, dzięki temu na pewno unikną plagiatu. Program będzie też bardzo użyteczny dla osób, które mają już pełny raport z JSA i próbują zgodnie z nim poprawić pracę.

Plag.pl – opinia: drogi, ale skuteczny. Rozpoznał jako plagiat zarówno fragmenty, w których zmieniłam co 5 słowo, jak i część fragmentów, gdzie zmieniłam co 4 słowo. Nie wyłapał natomiast tych, gdzie zastosowałam zmianę szyku zdania i naturalną parafrazę. Wielkim plusem programu jest możliwość pobrania raportu w .doc i docx z zaznaczonymi na czerwono fragmentami, rozpoznanymi jako plagiat. Dodatkowo program jako jedyny nie usuwa formatowania, chociaż przy dużych plikach może się ono „rozsypać”.
Pobierz uzyskany wynik
Plagiat.pl – opinia: względnie tani i skuteczny – wykrył plagiat w tekście, gdzie zmieniłam co 5 słowo oraz, co najważniejsze, w obszernych fragmentach tekstu, gdzie zastosowałam naturalną parafrazę. Nie potrafi rozpoznać plagiatu jeżeli zmienimy szyk zdania. Raport generuje się szybko, a znalezione źródła są prawidłowe. Jest to polski produkt i istnieje na rynku już wiele lat, co przemawia na jego korzyść. Systemy antyplagiatowe, korzystające z polskich słowników i opracowanych przez polskich naukowców modeli języka polskiego mają wyższą skuteczność wykrywania plagiatu.
Pobierz uzyskany wynik
**** – opinia: względnie tani i mało skuteczny, mało użyteczny dla studenta. Wymaga zainstalowania dodatkowego rozszerzenia. Najbardziej niepokojące jest to, że nie przypisał on trafnych źródeł dla wykorzystanego tekstu.
Jaki Antyplagiat online ma wybrać student?
Jeżeli masz raport z JSA, albo jesteś na etapie pisania pracy to zdecydowanie najlepszym systemem antyplagiatowym będzie Wrona, jeżeli jednak nie posiadasz tekstu źródłowego lub raportu z JSA najlepiej by było, żebyś skorzystał zarówno z plagiatu.pl jak i z programu plag.pl , bo ich algorytmy trochę się od siebie różnią, jednak oba programy skutecznie wykrywają plagiat. Plagiat.pl jest zdecydowanie tańszy, natomiast w Plag.pl możesz skorzystać z wygodnej opcji automatycznego zaznaczenia tekstu, który jest plagiatem, bezpośrednio w Twoim pliku .doc .
Jak działają programy antyplagiatowe online?
Każdy program antyplagiatowy to jakiś rodzaju algorytmu. Jak taki algorytm jest zbudowany? Żeby to wytłumaczyć należy przyjrzeć się jak jest skontruowany każdy polski (i nie tylko) tekst. Możemy wyróżnić w nim kilka jednostek. Znaki, będące literami lub znakami interpunkcyjnymi, słowa, składające się z liter oraz zdania składające się za słów i znaków przystankowych. Gdybyśmy chcieli zatem stworzyć algorytm badający podobieństwo pomiędzy tekstami mielibyśmy następujące możliwości:
Tak wyglądało to kiedyś:
1. Rozpoznawanie identycznych ciągów znaków o danej długości
Tak wyglądały programy antyplagiatowe na początku, ale studenci wpadli na genialny pomysł zastępowania spacji dowolną literą zamalowaną na biało, żeby oszukać program, takich skutecznych rozwiązań było kilka, dlatego wymyślono nowy sposób
2. Rozpoznawanie identycznych ciągów słów o danej długości
Tak wyglądało to jeszcze do końca 2018 roku. Metoda była prosta i względnie skuteczna, jednak poprawa plagiatu, też nie należała do szczególnie trudnych, wystarczyło zmienić np., co piąte słowo, albo zmienić szyb zdania, żeby program nie rozpoznał podobieństwa.
Tak wygląda to dziś:
Obecnie programy antyplagiatowe mają zaimplementowanych kilka z niżej wymienionych funkcji, ALE dotyczy to tylko rozbudowanych systemów np. uczelnianych. Dlaczego? Dowiesz się w dalszej części artykułu.
- Rozpoznawanie skupisk podobnych słów, bez względu na ich kolejność w tekście
- Sprowadzanie słów do mianownika, bezokolicznika – czili ignorowanie odmiany słów
- Zaimplementowanie bazy synonimów
- Wykorzystanie stylometrii czyli próby szukania spersonalizowanego stylu, wyznacznikami takiego stylu może być na przykład: średnia długość zdań, częstotliwość korzystania z określonych środków retorycznych np. metafory. Ta metoda na razie raczkuje, ale może okazać się przełomowa w przyszłości.
- Próby analizy semantycznej – znaczenia tekstu
Bazy porównawcze
Każdy program antyplagiatowy musi porównać otrzymany tekst z innymi wcześniej powstałymi pracami. Programy wykorzystują w tym celu ogólno dostępne zasoby internetowe, własne bazy np. artykułów naukowych albo bazy pracy uczelnianych.
Takie szczegółowe porównania są skuteczne jednak bardzo czasochłonne i niewykonalne w przypadku porównywaniapracy z tak dużą bazą jak ORPPD i zasoby internetowe. Wynika to z tego, że wymagają dokonania operacji na obydwu fragmentach tekstu,np. sprowadzenia słów do mianownika. Najbardziej zaawansowane techniki są najskuteczniejsze, ale można je wykorzystać jedynie przyporównaniach 1:1.Nasze komputery nie są w stanie wykonywać takich operacji na dużych zbiorach danych w czasie jaki by nas satysfakcjonował.
Takie porównanie mogłoby trwać np. rok. Jak zatem rozwiązują ten problem zaawansowane systemy antyplagiatowe takie jak JSA? Najpierw przeszukują obszerne bazy pod kątem prawdopodobnie podobnych tekstów, żeby następnie dokonać bardziej zaawansowanych porównań w pracach 1:1. W tym celu stosują metodę fingerprint, czyli kompresują teksty przy użyciu metody n-gramów. Ngram to człon o dowolnej długości.
Dowolny tekst można skompresować wyłaniając z niego np
-
Słowa, wtedy zdanie: „Ola poszła do przedszkola” będzie składało się z
następujących:
- 1-gramów: Ola, poszła, do, przedszkola
- 2-gramów: Ola poszła, poszła do, do przedszkola
- 3-gramów: Ola poszła do, poszła do przedszkola
-
Ciągi znaków o danej długości, wtedy zdanie „Ola poszła do przedszkola” będzie
się składało z:
- następujących 3 gramów: Ola, laspacja, aspacjap, spacjapo…
Nagram
Ngramem może być dowolna część tekstu, słowo, litera, zdanie, ciąg słów itp. Powstał nawet cały ngramowy model języka Polskiego (zobacz tu).W praktyce wygląda to następująco:
-
Wszystkie litery alfabetu łacińskiego możemy sprowadzić np. do jedno, dwu lub
trzy gramowych członów. Otrzymamy wtedy coś takiego:
a-1 , b-2, c-3…..
aa-11, ab 12, ac-13
aaa- 111, aaab- 112, aac – 113…
-
Możemy to uprościć jeszcze bardziej i nazwać tylko nasze 3-gramowe człony, tak
uzyskamy:
Aaa-1 aab- 2, aac- 3, aad-4….
Następnie możemy skonstruować sobie zbiór algorytmów, które, za prawdopodobnie podobne oznaczą np.:
- Wszystkie fragmenty o długości 100 3gramów, w których wystąpiło 20 identycznych 3 gramów.
- Fragmenty o dowolnej długości, w których znaleziono ciąg 5 identycznych 3gramów.
To jeden ze sposobów optymalizacji przetwarzania tekstu. Możemy całą naszą bazę referencyjną zapisać, tak, żeby maksymalnie przyspieszyć ostateczny proces poszukiwania prawdopodobnie podobnych tekstów. Jeżeli jednak nie posiadamy własnej bazy, ale korzystamy z przeszukiwania Internetu w czasie rzeczywistym, ta metoda może się okazać niewystarczająca. Wtedy skuteczne może być np. przeszukiwanie zasobów pod kątem nasycenia słowami kluczowymi. Warto zwrócić uwagę, na to, że systemy, które opierają swój algorytm jedynie o przeszukiwanie Internetu w czasie rzeczywistym są zazwyczaj gorzej zoptymalizowanie i mają niższą skuteczność. Ponadto opierają się zazwyczaj o wyniki wyszukiwarki Google, dlatego mogą generować inne raporty dla tych samych tekstów porównanych w większych odstępach czasu np. na przestrzeni 2 miesięcy. Wynika to z tego, że wyniki w wyszukiwarce Google ulegają dynamicznym zmianom.
Nadal Potrzebujesz
POMOCY W PISANIU ?
Nazywam się Dorota Wrona. Moją misją jest pomoc studentom. Skorzystaj z ponad 25 lat doświadczenia w pisaniu i redakcji tekstów naukowych
Umów się na darmowe konsultacje